---
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
library_name: nemo
datasets:
- nvidia/Granary
- YTC
- Yodas2
- LibriLight
- librispeech_asr
- fisher_corpus
- Switchboard-1
- WSJ-0
- WSJ-1
- National-Singapore-Corpus-Part-1
- National-Singapore-Corpus-Part-6
- vctk
- voxpopuli
- europarl
- multilingual_librispeech
- fleurs
- mozilla-foundation/common_voice_8_0
- MLCommons/peoples_speech
- google/speech_commands
thumbnail: null
tags:
- speech-recognition
- cache-aware ASR
- automatic-speech-recognition
- streaming-asr
- speech
- audio
- FastConformer
- RNNT
- Parakeet
- ASR
- pytorch
- NeMo
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: nemotron-speech-streaming-en-0.6b
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: AMI
type: ami
config: ihm
split: test
metrics:
- name: WER (1.12s frame size)
type: wer
value: 11.58
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Earnings22
type: earnings22
split: test
metrics:
- name: WER (1.12s frame size)
type: wer
value: 12.48
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Gigaspeech
type: gigaspeech
split: test
metrics:
- name: WER (1.12s frame size)
type: wer
value: 11.45
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech test-clean
type: librispeech_asr
config: clean
split: test
metrics:
- name: WER (1.12s frame size)
type: wer
value: 2.31
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech test-other
type: librispeech_asr
config: other
split: test
metrics:
- name: WER (1.12s frame size)
type: wer
value: 4.75
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: SPGI Speech
type: spgispeech
split: test
metrics:
- name: WER (1.12s frame size)
type: wer
value: 2.62
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: TEDLIUM
type: tedlium
split: test
metrics:
- name: WER (1.12s frame size)
type: wer
value: 4.5
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: VoxPopuli
type: voxpopuli
config: en
split: test
metrics:
- name: WER (1.12s frame size)
type: wer
value: 7.57
metrics:
- wer
pipeline_tag: automatic-speech-recognition
---
# Nemotron Speech ASR
[](#model-architecture)
| [](#model-architecture)
| [](#datasets)
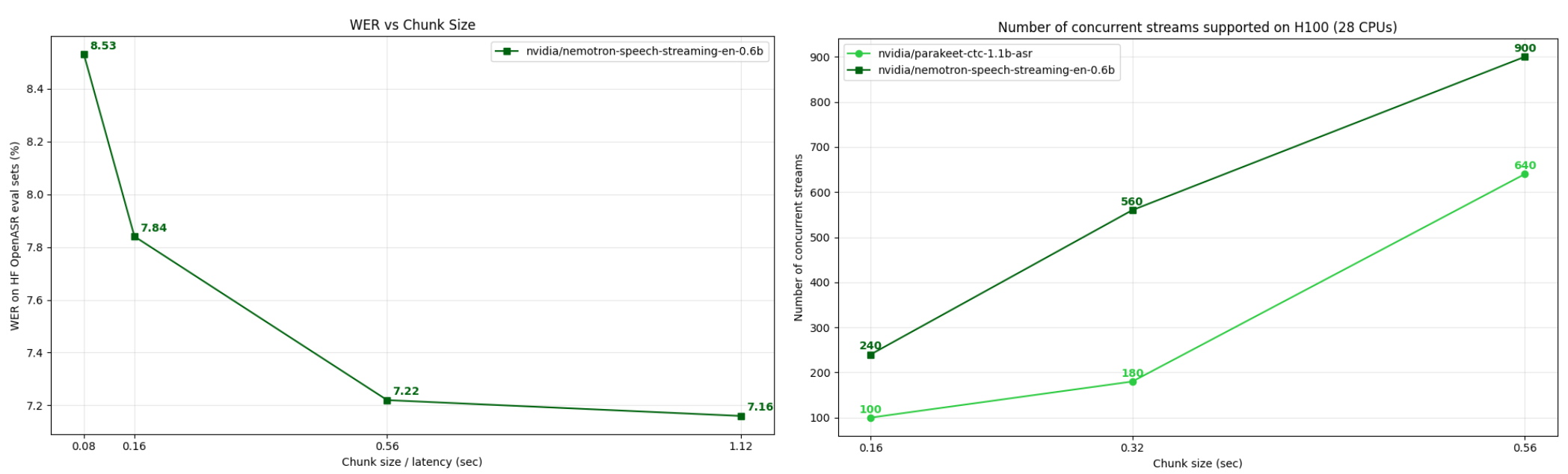
Nemotron-Speech-Streaming-En-0.6b is the first unified model in the Nemotron Speech family, engineered to deliver high-quality English transcription across both low-latency streaming and high-throughput batch workloads. The model natively supports punctuation and capitalization and offers runtime flexibility with configurable chunk sizes, including 80ms, 160ms, 560ms, and 1120ms.
Why Choose nvidia/nemotron-speech-streaming-en-0.6b?
* **Native Streaming Architecture:** Cache-aware design enables efficient processing of continuous audio streams, designed and optimized for low-latency voice agent applications interaction.
* **Improved Operational Efficiency:** Delivers superior throughput compared to traditional buffered streaming approaches. This allows for a higher number of parallel streams within the same GPU memory constraints, directly reducing operational costs for production environments.
* **Dynamic Runtime Flexibility:** Enables you to choose the optimal operating point on the latency-accuracy Pareto curve at inference time. No re-training is required to adjust for different use-case requirements.
* **Punctuation & Capitalization:** Built-in support for punctuation and capitalization in output text
Nemotron-speech-streaming-en-0.6b allows users to choose the optimal operating point on the latency-accuracy pareto curve at inference time, without requiring any re-training. Further, the cache-aware streaming mechanism scales much better than buffered streaming approaches, consistently outperforming production models like parakeet-ctc-1_1b-asr across chunk sizes.
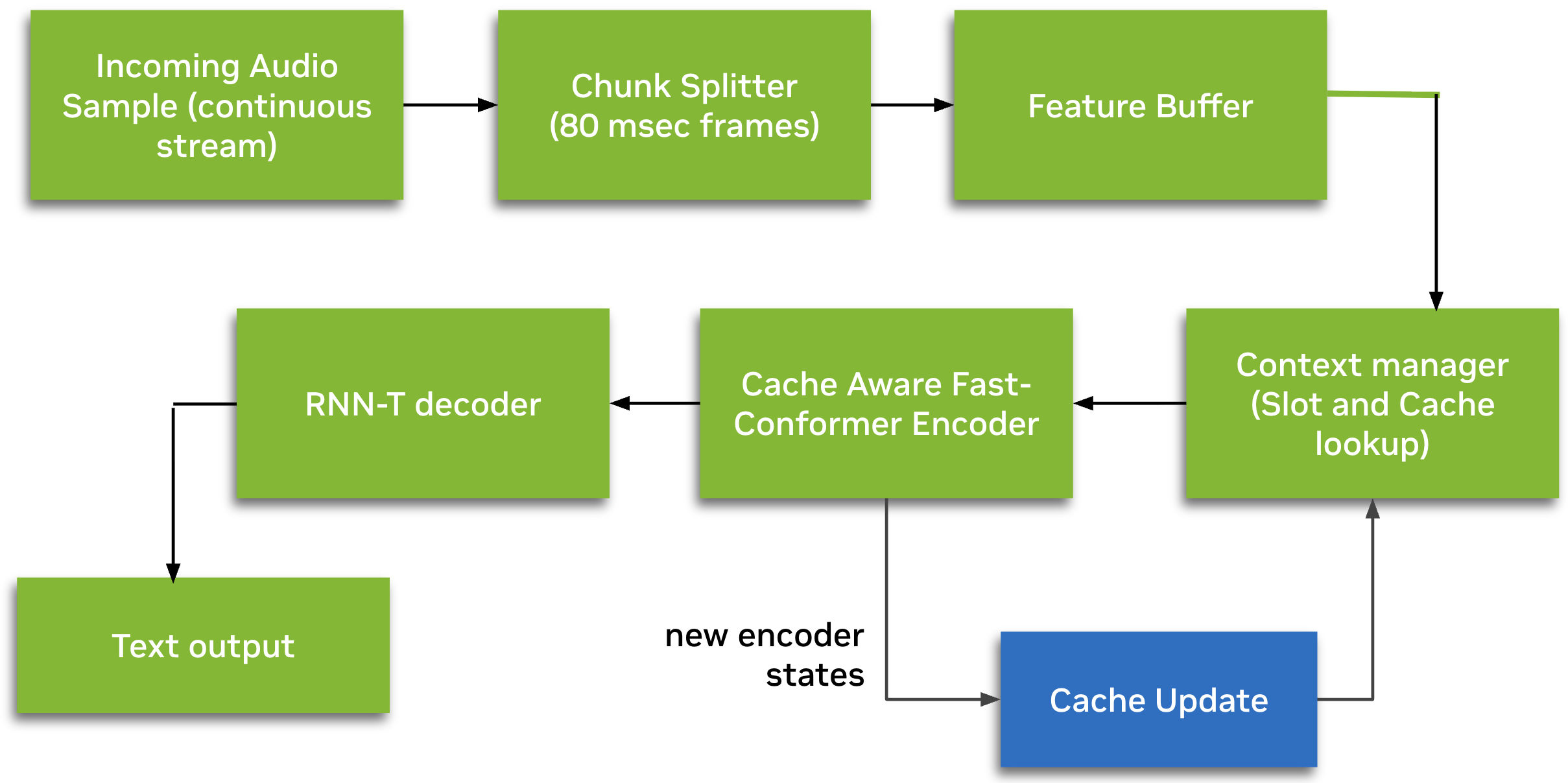
This model consists of a cache-aware streaming 🦜 Parakeet (FastConformer) encoder with an RNN-T decoder. It is designed for real-time speech-to-text applications where low latency is critical, such as voice assistants, live captioning, and conversational AI systems. Unlike traditional "buffered" streaming, the cache-aware architecture enables continuous transcription by processing only new audio chunks while reusing cached encoder context. This significantly improves computational efficiency and minimizes end-to-end delay without sacrificing accuracy.
🗣️ **Experience `Nemotron-Speech-Streaming-En-0.6b` in action** here: [https://huggingface.co/spaces/nvidia/nemotron-speech-streaming-en-0.6b](https://huggingface.co/spaces/nvidia/nemotron-speech-streaming-en-0.6b)
This model is ready for commercial/non-commercial use.
Read more about the model in the [dev blog](https://huggingface.co/blog/nvidia/nemotron-speech-asr-scaling-voice-agents) and check out the [paper](https://arxiv.org/abs/2312.17279).
## Explore more from NVIDIA:
For documentation, deployment guides, enterprise-ready APIs, and the latest open models—including Nemotron and other cutting-edge speech, translation, and generative AI—visit the NVIDIA Developer Portal at [developer.nvidia.com](https://developer.nvidia.com/).
Join the community to access tools, support, and resources to accelerate your development with NVIDIA's NeMo, Riva, NIM, and foundation models.
What is [Nemotron](https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/)?
NVIDIA Developer [Nemotron](https://developer.nvidia.com/nemotron)
[NVIDIA Riva Speech](https://developer.nvidia.com/riva?sortBy=developer_learning_library%2Fsort%2Ffeatured_in.riva%3Adesc%2Ctitle%3Aasc#demos)
[NeMo Documentation](https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/asr/models.html)
## Access Model Inference and Examples:
* Deploy the Nemotron Speech ASR endpoint on [Modal](https://github.com/modal-projects/modal-nvidia-asr)
* Build local voice agent using [Daily’s framework](https://github.com/pipecat-ai/nemotron-january-2026)
## Model Architecture
**Architecture Type:** FastConformer-CacheAware-RNNT
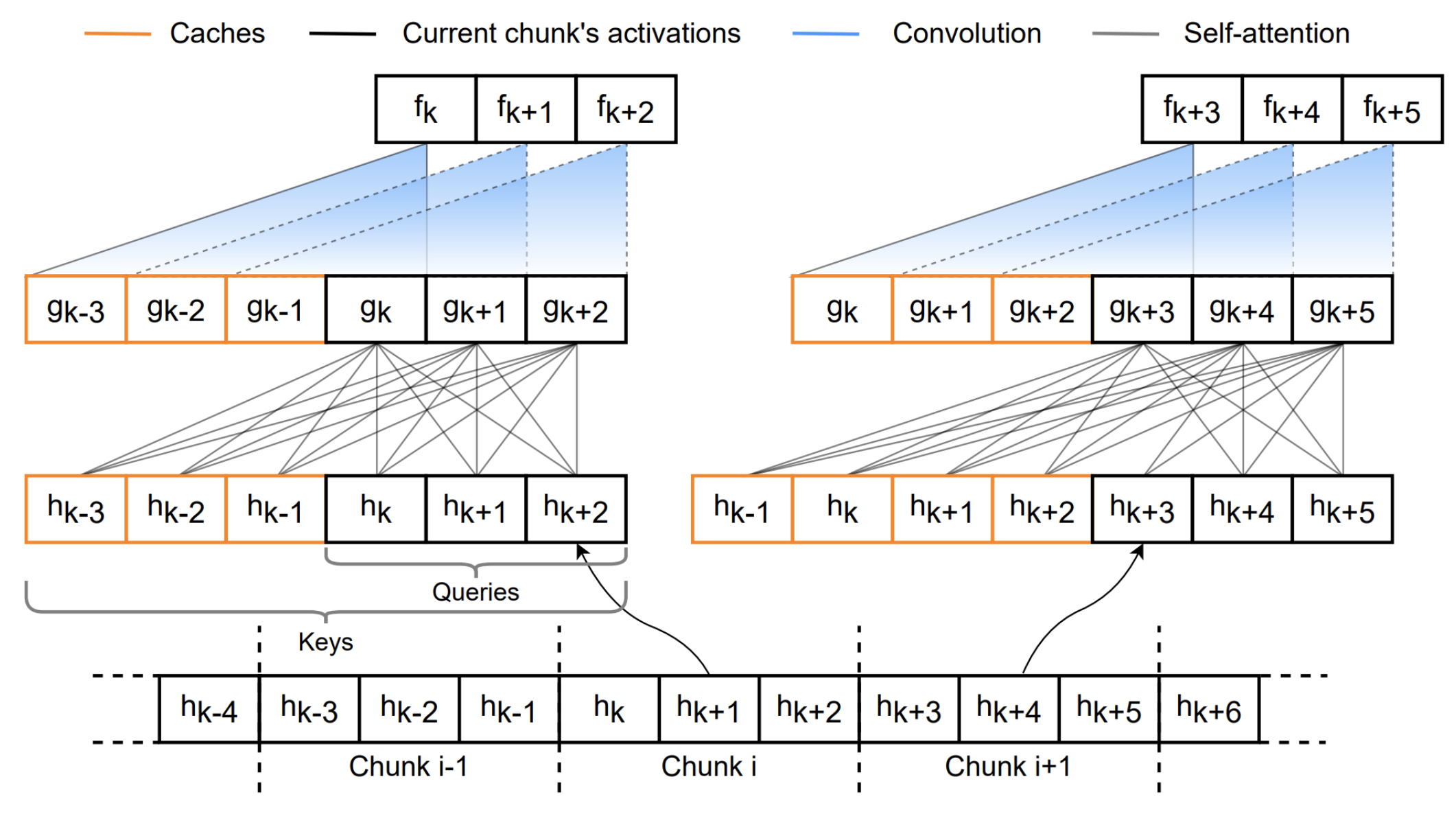
The model is based on the Cache-Aware [1] FastConformer [2] architecture with 24 encoder layers and an RNNT (Recurrent Neural Network Transducer) decoder. The cache-aware streaming design enables efficient processing of audio in chunks while maintaining context from previous frames. Unlike buffered inference, this model maintains caches for all encoder self-attention and convolution layers. This enables reuse of hidden states at every streaming step, where cached activations eliminate redundant computations. As a result, there are no overlapping computations; each processed frame is strictly non-overlapping.
The caching schema of self-attention and convolution layers for consecutive chunks is as follows. For more details, please refer to [1].
**Network Architecture:**
- Encoder: Cache-Aware FastConformer with 24 layers
- Decoder: RNNT (Recurrent Neural Network Transducer)
- Parameters: 600M
## NVIDIA NeMo
To train, fine-tune or perform inference with this model, you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo)[4]. We recommend you install it after you've installed Cython and latest PyTorch version.
```bash
apt-get update && apt-get install -y libsndfile1 ffmpeg
pip install Cython packaging
pip install git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
```
## How to Use this Model
The model is available for use in the NeMo Framework, and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Loading the Model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/nemotron-speech-streaming-en-0.6b")
```
### Streaming Inference
You can use the cache-aware streaming inference script from NeMo - [NeMo/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py](https://github.com/NVIDIA-NeMo/NeMo/blob/main/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py)
``` bash
cd NeMo
python examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path= \
dataset_manifest= \
batch_size= \
att_context_size="[70,13]" \ #set the second value to the desired right context from {0,1,6,13}
output_path=
```
You can also run streaming inference through the pipeline method, which uses [NeMo/examples/asr/conf/asr_streaming_inference/cache_aware_rnnt.yaml](https://github.com/NVIDIA-NeMo/NeMo/blob/main/examples/asr/conf/asr_streaming_inference/cache_aware_rnnt.yaml) configuration file to build end‑to‑end workflows with punctuation and capitalization (PnC), inverse text normalization (ITN), and translation support.
```python
from nemo.collections.asr.inference.factory.pipeline_builder import PipelineBuilder
from omegaconf import OmegaConf
# Path to the cache aware config file downloaded from above link
cfg_path = 'cache_aware_rnnt.yaml'
cfg = OmegaConf.load(cfg_path)
# Pass the paths of all the audio files for inferencing
audios = ['/path/to/your/audio.wav']
# Create the pipeline object and run inference
pipeline = PipelineBuilder.build_pipeline(cfg)
output = pipeline.run(audios)
# Print the output
for entry in output:
print(entry['text'])
```
_______
### Setting up Streaming Configuration
Latency is defined by the `att_context_size` param, where att_context_size = `{num_frames_left_context, num_frame_right_context}`, all measured in **80ms frames**:
* [70, 0]: Chunk size = 1 (1 × 80ms = 0.08s)
* [70, 1]: Chunk size = 2 (2 × 80ms = 0.16s)
* [70, 6]: Chunk size = 7 (7 × 80ms = 0.56s)
* [70, 13]: Chunk size = 14 (14 × 80ms = 1.12s)
Here, chunk size = current frame + right context; each chunk is processed in non-overlapping fashion.
### Input
This model accepts single-channel (mono) audio sampled at 16,000 Hz. At least 80ms duration is required.
### Output
The model outputs English text transcriptions with punctuation and capitalization. The output text might be empty if input audio doesn't contain any speech.
## Datasets
### Training Datasets
The majority of the training data comes from the English portion of the Granary dataset [3]:
- YouTube-Commons (YTC) (109.5k hours)
- YODAS2 (102k hours)
- Mosel (14k hours)
- LibriLight (49.5k hours)
In addition, the following datasets were used:
- Librispeech 960 hours
- Fisher Corpus
- Switchboard-1 Dataset
- WSJ-0 and WSJ-1
- National Speech Corpus (Part 1, Part 6)
- VCTK
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual Librispeech (MLS EN)
- Mozilla Common Voice (v11.0)
- Mozilla Common Voice (v7.0)
- Mozilla Common Voice (v4.0)
- People Speech
- AMI
**Data Modality:** Audio and text
**Audio Training Data Size:** 285k hours
**Data Collection Method:** Human - All audios are human recorded
**Labeling Method:** Hybrid (Human, Synthetic) - Some transcripts are generated by ASR models, while some are manually labeled
### Evaluation Datasets
The model was evaluated on the HuggingFace ASR Leaderboard datasets:
- AMI
- Earnings22
- Gigaspeech
- LibriSpeech test-clean
- LibriSpeech test-other
- SPGI Speech
- TEDLIUM
- VoxPopuli
## Performance
## ASR Performance (w/o PnC)
ASR performance is measured using the Word Error Rate (WER). Both ground-truth and predicted texts are processed using [whisper-normalizer](https://pypi.org/project/whisper-normalizer/) version 0.1.12.
The following tables show the WER on the [HuggingFace OpenASR leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard) datasets:
### Word Error Rate (WER) for chunk size of 1.12s
| | Average | AMI | Earnings22 | Gigaspeech | LS-test-clean | LS-test-other | SPGI | TEDLIUM | VoxPopuli |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| **WER (%)** | **7.16** | 11.58 | 12.48 | 11.45 | 2.31 | 4.75 | 2.62 | 4.50 | 7.57 |
### WER for chunk size of 0.56s
| | Average | AMI | Earnings22 | Gigaspeech | LS-test-clean | LS-test-other | SPGI | TEDLIUM | VoxPopuli |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| **WER (%)** | **7.22** | 11.69 | 12.61 | 11.43 | 2.40 | 4.97 | 2.64 | 4.46 | 7.59 |
### WER for chunk size of 0.16s
| | Average | AMI | Earnings22 | Gigaspeech | LS-test-clean | LS-test-other | SPGI | TEDLIUM | VoxPopuli |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| **WER (%)** | **7.84** | 13.88 | 13.61 | 12.12 | 2.43 | 5.33 | 2.82 | 4.80 | 7.72 |
### WER for chunk size of 0.08s
| | Average | AMI | Earnings22 | Gigaspeech | LS-test-clean | LS-test-other | SPGI | TEDLIUM | VoxPopuli |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| **WER (%)** | **8.528** | 16.05 | 14.6 | 12.92 | 2.55 | 5.79 | 3.01 | 5.07 | 8.23 |
## Software Integration
**Runtime Engine:** NeMo 25.11
**Supported Hardware Microarchitecture Compatibility:**
- NVIDIA Ampere
- NVIDIA Blackwell
- NVIDIA Hopper
- NVIDIA Volta
**Test Hardware:**
- NVIDIA V100
- NVIDIA A100
- NVIDIA A6000
- DGX Spark
**Preferred/Supported Operating System(s):** Linux
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report model quality, risk, security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## References
[1] [Stateful Conformer with Cache-based Inference for Streaming Automatic Speech Recognition](https://arxiv.org/abs/2312.17279)
[2] [Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition](https://arxiv.org/abs/2305.05084)
[3] [NVIDIA Granary](https://huggingface.co/datasets/nvidia/Granary)
[4] [NVIDIA NeMo Framework](https://github.com/NVIDIA/NeMo)